
Datum geplaatst: 29 juli 2024
Voor veel gemeentes is duidelijk inzicht krijgen in de locatie en de hoeveelheid zonnepanelen op daken een lastige zaak. De wet om aangeschafte zonnepanelen te registreren wordt niet altijd gehandhaafd, wat kan leiden tot incomplete datasets. Om dit probleem op te lossen heeft Rienk voor zijn afstudeerthesis een AI model ontwikkeld dat vanuit luchtfoto’s automatisch zonnepanelen kan herkennen.
De basis voor dit model was een Convolutional Neural Network (CNN). Een CNN is een neuraal netwerk architectuur dat gebruikt maakt van leerbare filters die op verschillende lagen op de foto worden toegepast. Deze filters (of “kernels”) leren om zogeheten “features” uit een afbeelding te onttrekken, zoals patronen of texturen, die vervolgens gebruikt kunnen worden om te leren of een foto een zonnepaneel bevat, en waar deze zich bevindt.
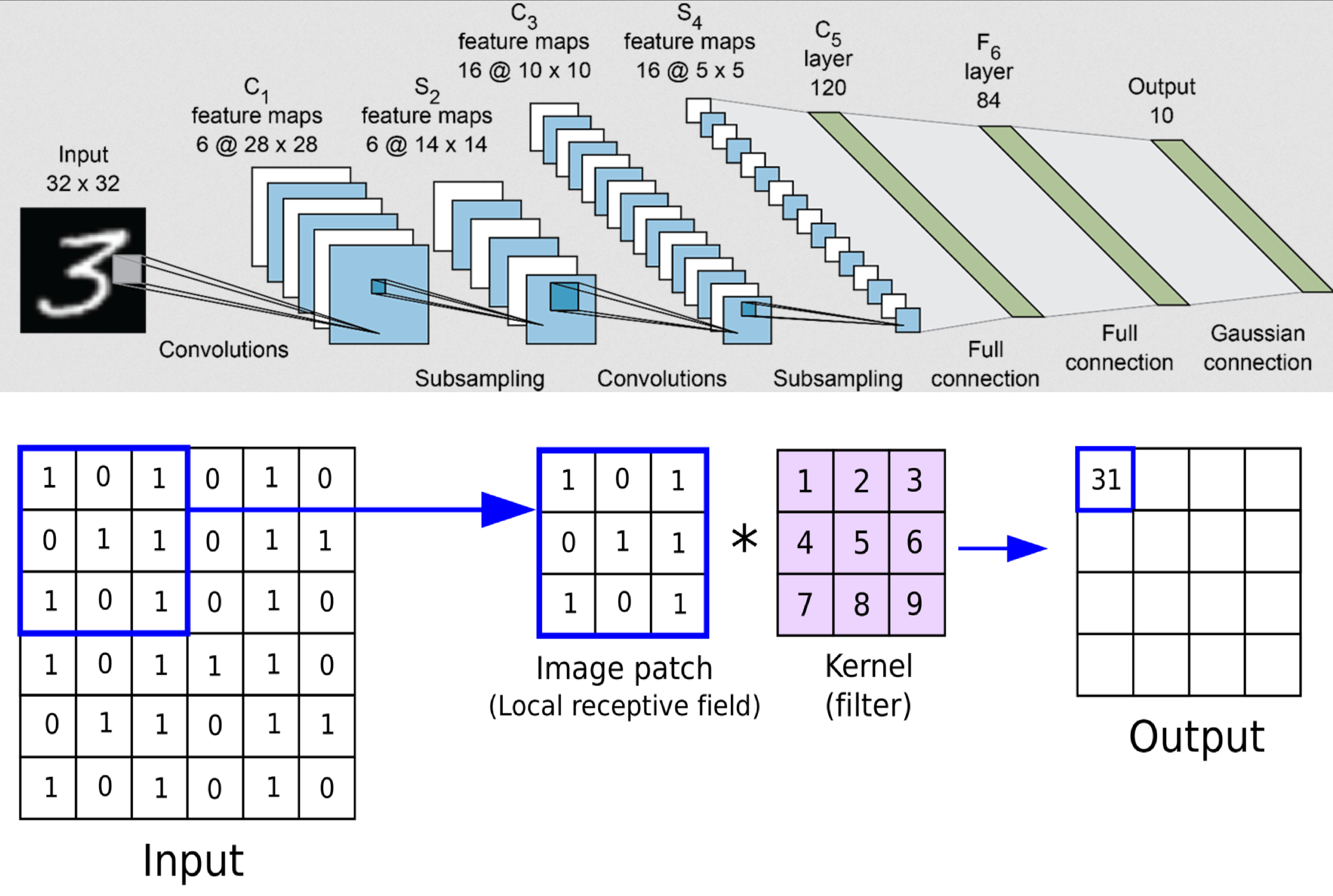
Het trainen van zo’n model om zonnepanelen te herkennen kost echter grote hoeveelheden handmatig gelabelde pixel-precieze voorbeelden van zonnepanelen, die veel tijd kosten om te maken. Een oplossing voor dit probleem is technieken te incorporeren waarmee ook gebruik gemaakt kan worden van niet gelabelde, of minder precies gelabelde data, waardoor minder gelabelde data nodig is. Deze technieken staan bekend als semi- en weakly-supervised leren.
In het geval van semi-supervised leren wordt een set van niet gelabelde data gebruikt ter aanvulling op een set gelabelde data. De niet gelabelde data wordt gebruikt door twee licht aangepaste versies van dezelfde foto door het model te laten verwerken, en het model te leren hierop dezelfde voorspelling te maken. Dit houdt het model consistent en verbeterd de precisie. Zo kan naast een kleine set gelabelde data ook waarde worden gehaald uit data die niet gelabeld hoeft te worden.
Weakly-supervised leren gaat er van uit dat er wel labels beschikbaar zijn, maar op een lager niveau dan de taak die geleerd moet worden. In dit geval is de taak om per pixel in een foto te bepalen of deze een zonnepaneel afbeeld, maar gebruiken we labels die aangeven of er op een foto een zonnepaneel aanwezig is, maar niet waar. Hier kan gebruik worden gemaakt van algemene modellen die een foto opsplitsen in segmenten zonder te weten welke segmenten zonnepanelen zijn. Daarnaast kunnen Class Activation Maps (CAM) gebruikt worden om van een classificatie model op te vragen welke pixels waarschijnlijk zonnepanelen bevatten. Door deze modellen te combineren kunnen we segmenten vinden met zonnepanelen. Zie de foto hieronder voor een overzicht van de procedure.
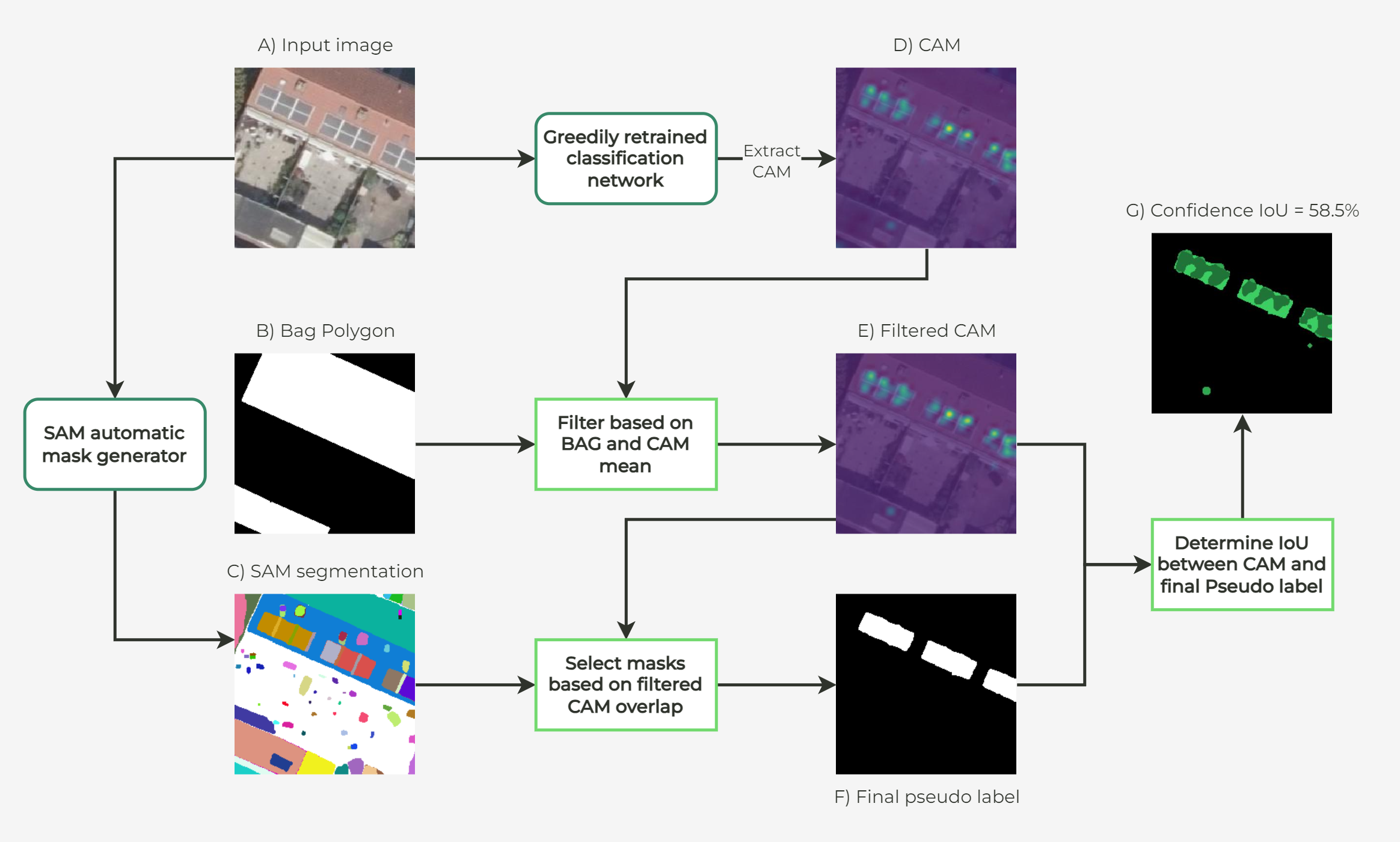
De resultaten van deze verschillende methodes lieten zien dat weakly-supervised leren wel minder handmatig werk vereist, maar daardoor minder precieze resultaten geeft. Semi-supervised leren daarentegen gaf betere resultaten dan zelfs de standaard methode van fully-supervised leren. De hoogste score behaalt op de testset was een Intersection over Union score van 73.3%. Dit betekent dat de voorspelde pixels voor ongeveer 73% overlap hadden met de zonnepanelen, ten opzichte van het totale oppervlakte van de voorspelling en de zonnepanelen samen. Binnenkort hopen we deze score nog verder uit te breiden met de lessen die we geleerd hebben uit dit onderzoek.
Met dit model zijn we in staat om binnen korte tijd een volledige gemeente in te scannen en te bepalen wat het geschatte oppervlakte zonnepanelen is per adres in de gemeente. Hiermee kan een inschatting worden gemaakt van de potentie voor groene energie opgewekt uit zonne-energie binnen een gemeente.
Interessant? Of benieuwd hoe dit in jouw gemeente van toepassing kan zijn? Neem contact met ons op via info@we-boost.nl.